Icecream PDF Converter extracts text to DOC, ODT, RTF
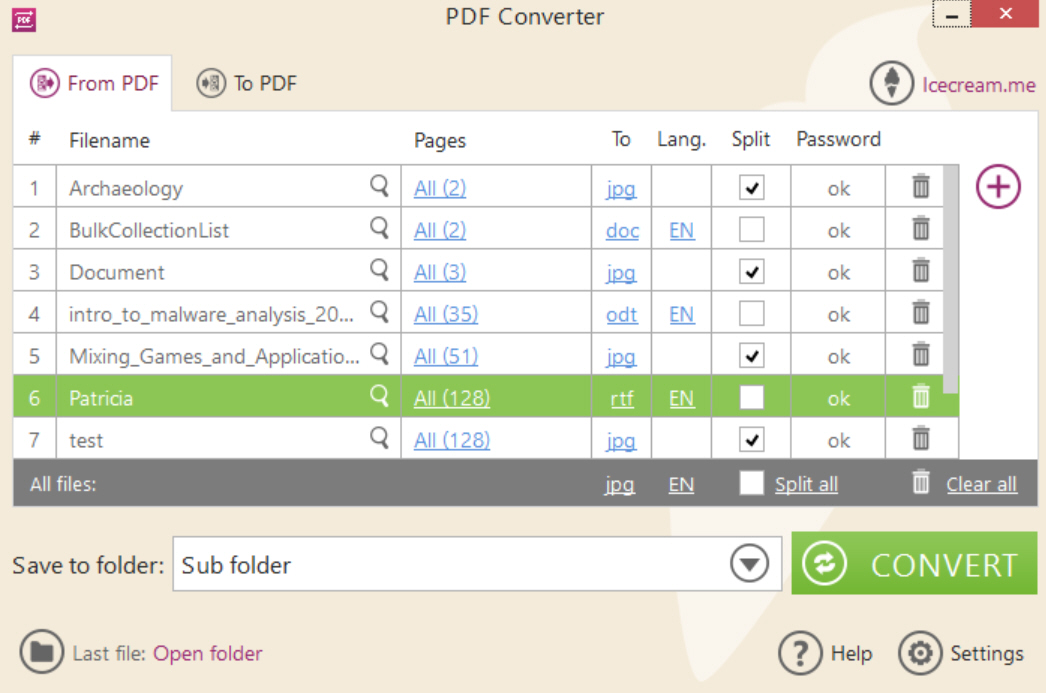
Utilities developer Icecream Apps has released Icecream PDF Converter 1.3, extending the program with new text extraction tools.
The program can now extract the text from one or more PDFs, saving it in DOC, ODT, RTF and TXT formats.
(The previous build had an option to save text as HTML. That never worked for us, at all, but it seems to be functional in this release.)
Our first impressions, based on very minimal testing, are mixed. PDF Converter successfully extracted the text from some of our PDFs, even if they’re image-based, thanks to a bundled copy of the open source OCR engine Tesseract. It’s not simply plain text, either: we ran a PDF to DOC conversion and our destination file had correctly bolded headings.
This didn’t quite work as we expected with mixed documents, though – mostly text, with some pictures. The program extracted the text correctly in our test files, but then displayed a sentence or two of binary garbage where the images used to be. That’s not the OCR engine’s fault – the images had no text to extract – but PDF Converter needs a smarter way to handle this situation, perhaps an option to ignore images when you’re only interested in document text.
Fortunately there’s still a lot to like here, with Icecream PDF Converter able to convert PDFs to many image formats, as well as create PDFs from Office documents, images, eBooks and more. It’s also entirely adware-free – unusual for this type of application – and safe to try out, if you’d like to see how it works for you.