
Why data lineage matters and why it's so challenging

Change introduces risk. It’s one of those foundational principles of software development that most of us learned very early in our careers. Nevertheless, it always seems to keep cropping up in spite of those repeated life lessons. Our inability to foresee the impact of changes, even small ones, often leads to negative outcomes.
As the complexity of interconnected IT systems has increased, this problem has grown worse. It’s harder and harder to predict how even a small modification might impact systems upstream or downstream of the change. Data lineage accomplishes that, but it’s extraordinarily difficult to do data lineage well.
Why Data Lineage Matters
In the old world, data resided in silos with relatively few connection points between them. Today, data flows multi-directionally among multiple systems. Many of those systems share data with external organizations, which means that information subsequently flows to internal systems there, as well. Consequently, it’s easier than ever to overlook the impact of a single change on multiple other systems.
Imagine, for example, that your company provides a mobile app that enables customers to quickly and easily request a new service call. In the past, your customers could specify which product variant they owned. Your design team has determined that since you already have that information in your CRM database, you no longer need to collect it from users of the mobile app.
You’ve been tasked with simplifying the app, so you remove that input field and replace it with a query that pulls the customers’ product information from your CRM. Theoretically, the resulting work tickets should include all of the information that your field service personnel need to get the job done.
Unfortunately, there’s a problem; some of the customers’ product records in your CRM system contain null values. Your mobile app is querying that information, but it’s delivering invalid results to your ticketing system. Your field service personnel no longer know how to prepare for their next service call.
That might sound like a relatively simple problem of data quality -- one that might have been foreseen if someone had been more thorough about vetting the CRM data. Even that might not have solved the problem, though, if null values in the CRM database were not introduced until later. If customer data from a newly acquired company is merged into your CRM system, for example, you might not have product information tied to those new records.
Sometimes these issues are more difficult to predict, and they may not be apparent right away. Imagine what happens when your marketing team decides to redefine its customer segmentation criteria. A new data field is added to designate the customer category; then it’s populated with values for all customers and the old field is deprecated.
Unbeknownst to the marketing department, though, the company’s top executives are still looking at the old data. They’re using dashboards that rely on data from the deprecated field. New customers are being added every day, but no one is entering any values in the deprecated field. As a result, the executive team is looking at distorted data. Suddenly, the C-suite is tracking very different KPIs than the rest of the organization. What’s worse, no one even notices that there’s an issue until weeks or months after the fact.
Next, imagine a similar scenario, but instead of populating an executive dashboard, the source system is feeding data to the AI algorithms that drive customer recommendations on your e-commerce site. When AI is trained on flawed data -- or if the data changes materially in some way -- it can dramatically impact the effectiveness of that technology. In this case, it distorts your customer recommendation engine.
Tackling the Challenge With Data Lineage
Data lineage tools provide a systematic means of understanding the impact of changes by presenting a complete roadmap of potential implications, both upstream and downstream.
This amounts to risk reduction and cost control. If we can predict how changes might impact other systems, we can avoid creating problems like the ones we described earlier. That leads to less wasted effort, faster time-to-market and lower costs. We’re all familiar with the principle that says it’s faster and cheaper to solve a problem when you catch it early in the development process; data lineage provides a critical missing link, potentially ferreting out problems before they even reach QA.
There are benefits to data governance and regulatory compliance as well. When the European Union passed the General Data Protection Regulation (GDPR) back in 2016, it set off a chain of new requirements for systems that house personally identifiable information (PII). If a customer asks you to delete their data, you’re legally obligated to comply with that request. But what happens upstream and downstream of that change? Will it break anything? Or will some of the customer’s PII remain elsewhere in your systems, rendering you non-compliant with the law?
Data lineage addresses these questions by automating the process of detecting upstream and downstream effects. It provides clear auditability that can help determine where changes originated and how the data arrived at its current state.
Column-level data lineage is especially difficult because it requires that SQL queries be parsed to discern exactly what changed and how. This means tapping into database logs, but because there are so many database vendors -- each with their own unique SQL dialect -- parsing that information for various databases can be particularly challenging. As each of those SQL dialects evolves over time, data lineage tools must constantly be refined to accommodate those changes.
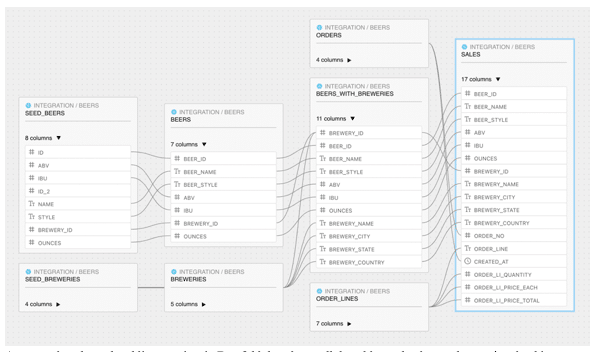
An example column-level lineage view that shows all the tables and columns that are involved in computing the sales table used for reporting in an imaginary e-commerce business selling craft beers.
As interconnected systems extend their reach even further and the flow of information accelerates, column-level data lineage will become more important. Today, it’s an extraordinarily useful tool that saves time, effort and money. Soon, data lineage will be indispensable.
Photo Credit: Pressmaster/Shutterstock

Alex Morozov is the chief technology officer and co-founder at Datafold, a data reliability platform that helps data teams deliver reliable data products faster. Visit Datafold at www.datafold.com/, and follow the company on Twitter, LinkedIn, Facebook and YouTube.