Three trends in tracking software delivery

Over the past decade, software has made giant leaps in allowing us to track, analyze and visualize the incredible amounts of data flowing across our organizations. Storage is rarely a bottleneck, advances in non-relational databases have helped capture growing volumes of data, and machine learning approaches promise to assist with deriving meaning and insight. Yet for the vast majority of large organizations, one kind of data seems immune to providing any kind of business intelligence -- the data for tracking software delivery itself.
Even organizations building the data analysis tools are struggling to find meaningful insights from the many tools and repositories that capture their own largest investment: building software. It would appear that the cobbler’s children have no shoes. Given all the advancements, how is this possible? And how can the situation change? If you have been tasked with providing insight or visibility into the data locked up in tools used to plan, code, deliver and support your organization’s software, here are three trends you should be aware of:
Trend 1: The heterogeneity and lack of standardization in dev tools will only get worse
We have learned to analyze complex data sets, and modern tools can do this at incredible scale and speed. However, there are some dimensions of complexity beyond data volume that can make analysis notoriously difficult. This is exactly what the software delivery tools landscape has landed, exhibiting the following dimensions of complexity:
- Number of tools and repositories: Due to an increasing specialization of roles and platforms, there are dozens of different tools in use today, with best-of-breed being the name of the game. For example, in analyzing sales and marketing data, you may get most of what you need by accessing the data in Salesforce and Marketo. To get the full picture on software delivery, expect to need to access a dozen or more tools.
- Change of tools over time: In part due to the best-of-breed needs of developers and other software specialists, the tool chains have been changing at a surprising speed. In large enterprise organizations, it is now common to have one or more new tools added each year, with decommissioning of tools lagging onboarding.
- Complexity of schemas and workflows: Also due to the number and complexity of the different software roles (a growing number of different kinds of developers, testers, infrastructure, support, design and delivery specialists), the tools themselves have become complex. This has translated to sophisticated schemas for the artifacts that need to be tracked (eg, features, defects, tickets) as well as sophisticated workflows for those artifacts, sometimes involved well over a dozen different steps.
- Project and team complexity: Different teams and projects often specialize the schemas and workflows that they use in order to tailor those to their delivery needs. This adds another dimension of complexity.
- Change in schemas, workflows, and teams over time: Building on the sophistication, teams continue to evolve and change schemas and workflows, turning those into a moving target as well, not only across the organization, but within each project and team.
Consider the most basic report of software delivery activity, such as listing the number of features delivered for each project or product over the past year. To generate this report, you need to be able to connect to each tool repository where feature delivery is being tracked. Depending on the level of heterogeneity, that can involve several conversations with the delivery teams, potentially across multiple lines of business. But that’s the easy part. Then, you need to be able to identify the data artifacts corresponding to features.
This step can involve dozens of discussions, because there is no single standard model by which teams define features. Then, you need to identify the workflow state for a feature to be "done". Due to the size and inconsistency in schemas, this can be very difficult. Add to this picture the monthly changes to schemas and workflows that teams will be doing, as well as adherence to those changes, and you have an intractable problem on your hands. You may succeed in getting this done for one team or product value stream, but if the organization is large, scaling all of the hard-wired data mapping, transformation and analysis to the organization, and ensuring it remains accurate, is likely to be impossible.
Trend 2: Modeling tools will emerge to create abstractions over heterogeneous tool chains
In Project to Product, I reported on the analysis of 308 enterprise organizations tool chains, where the findings summarized above were discovered. I realized that the problem is severe enough, that reporting directly from the software delivery tools themselves was a losing battle, just as much as expecting the organization or vendors to work to common standards was. There is just too much specialization across tools, teams and disciplines. What’s even more interesting is that, due to the dimensions of complexity listed above, mapping the data after it is collected is another losing battle. Instead, we need two things:
- An abstraction layer over the network of tools: This layer needs to specify the artifacts that we want to report on to the business, such as features, defects and risks.
- A mechanism for mapping activity to that layer: Once a specific artifact is created, such as a severe software defect, a mapping layer needs to translate the concrete fields and workflow states of that artifact into the more abstract and less granular states that we want to report on.
For example, the Flow Framework provides a tool and technology agnostic approach to doing this kind of mapping between the Tool Network layer and an Artifact Layer. Once done, the reporting can be done on the Artifact Layer directly, with the Integration Model between the two layers insulating the artifact layer from changes. Even more importantly, the responsibility of maintaining the Integration Model can be passed down to the teams deploying and maintaining (ie, constantly changing) the tools in the Tool Network. Combined, these activities make it possible to inspect the flow of value in software delivery, which the Flow Framework calls the Value Stream Network.
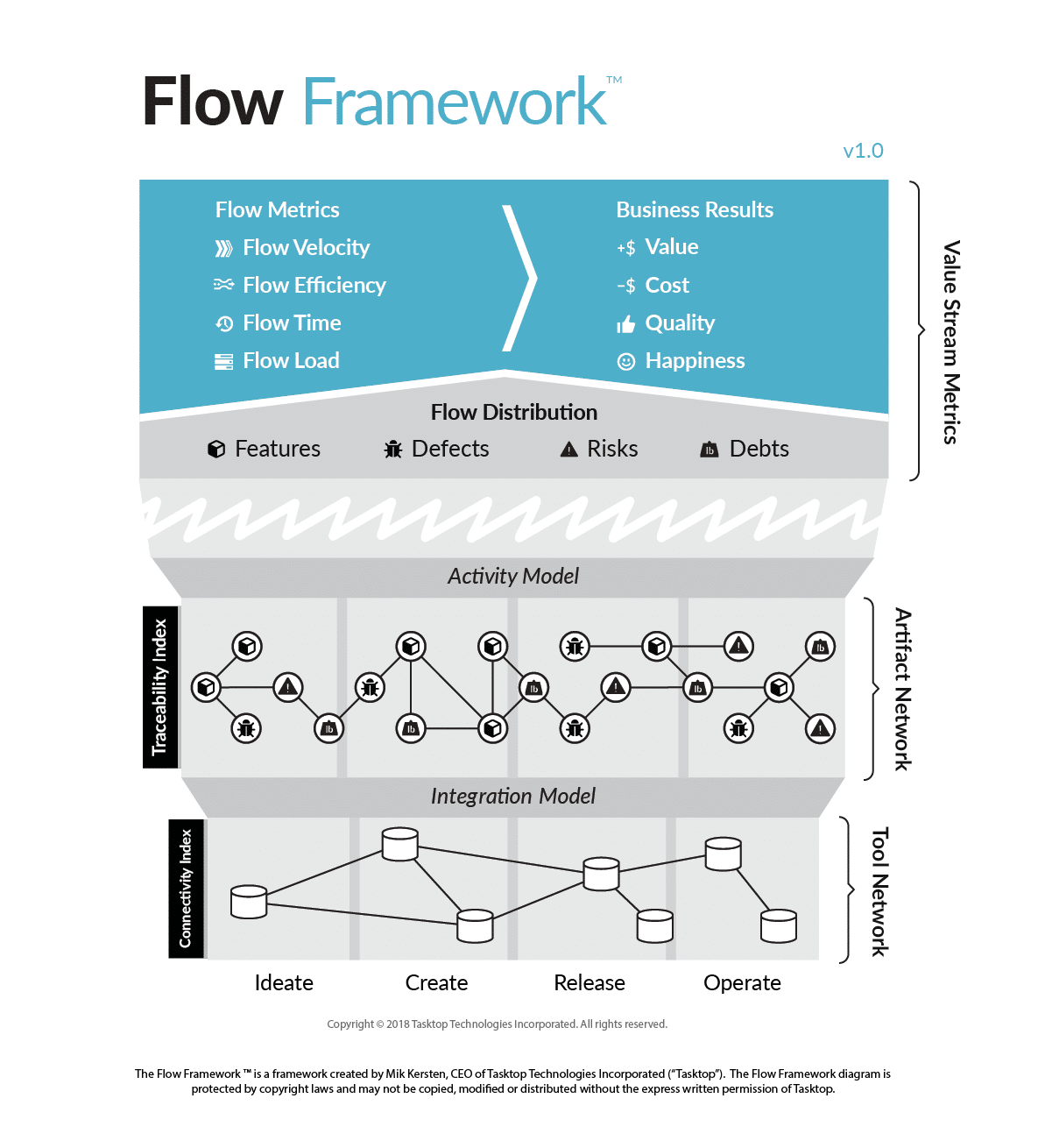
Trend 3: Organizations will define a common set of models and metrics to enable intelligence and analytics
Together, the Artifact Model and Value Stream Network make it possible to inspect, in real-time, the flow of activity across the software organization. By refining the Artifact Model, it becomes possible to provide business-level insights, and correlate those to other business metrics, such as Value and Cost, as visible in the top layer of the Flow Framework. With a consistent and normalized model of this sort, advanced analytics and machine learning become feasible as well, as the input data is clean, connected and can be correlated.
The problem with gaining visibility into software delivery is not the size of the data, it’s the complexity of the ever-changing structure of that data. The only way to handle that complexity is by introducing a new modeling layer, and assigning the mapping responsibility to the people who create, understand and modify that data. With this in place, the visibility problem turns from intractable, to an initiative we can apply our existing know-how and tools to. And with that in place in 2019, we can focus on the next great challenge of connecting the delivery data to business results.
Image credit: nd3000 / Shutterstock
 Dr. Mik Kersten is the CEO of Tasktop and author of Project to Product: How to Survive and Thrive in the Age of Digital Disruption with the Flow Framework. For more information, please visit, www.tasktop.com/mik-kersten.
Dr. Mik Kersten is the CEO of Tasktop and author of Project to Product: How to Survive and Thrive in the Age of Digital Disruption with the Flow Framework. For more information, please visit, www.tasktop.com/mik-kersten.