IT Systems Resiliency 101: What it means and 5 ways SMBs can adopt it

As overused as it may be, the old mantra still holds definitively true: you're only as strong as your weakest link. This goes for sports teams, business divisions, vehicles, and most anything else in life where multiple links make up the entity at large. It shouldn't be surprising that IT systems and networks follow the same logic.
Yet this very notion is what causes me to cringe when in discussions with new and existing clients. There is a large disconnect when it comes to the average small business owner, as to what technical improvements will actually lead to better stability and resiliency -- all encompassing what they truly care about: uptime.
I'm often on the listening end of hearing the joys of all the new hardware customers have decided to invest money in, yet are misguided as to how much of an effect these purchases will have on resiliency (aka uptime). Fleets of new Mac computers or Surface tablets. Shiny new desk phones. Or perhaps expensive new servers with the fancy bleeding edge Xeon processors and gobs of memory.
While worthy investments, and definitely mission-critical aspects to many businesses, these purchases do next to nothing when it comes to meeting the resiliency needs of most modern small businesses on their own. Resiliency is the ability for complex systems to stay operational in the face of disaster or outages. In the context of the average small business, this entails the aggregate whole of the core systems that power the IT backbone such as internet connectivity, server connectivity, application hosting, and more.
A $1500 Mac is as a crippled as a $250 Chromebook when your office server is down due to failed hard drives. Office 365 is great, except for when your only internet connection is down for half a day and no one can get emails internally. And that fancy $5K server is a massive paper weight if the network equipment it relies on has ethernet ports that fail in the middle of a busy day.
Before I get into the ways that we can enhance the resiliency of our IT systems, I want to shed light on the numerous examples of what this concept looks like in everyday life. Simple analogies make even tough IT concepts easy to understand.
Resiliency in the Real World -- How Does it Look?
As an infrastructure geek, resiliency and redundancy are things I am thinking of before comparing any of the finer specs on major IT systems for clients like networking equipment, servers, cloud IaaS, or similar undertakings. But the "average joe" doesn't always realize the how or what behind what solves these needs -- that's my job to spec, compare, and present as a digestible solution in plain terms.
Resilient systems, as I mentioned previously, are far from being relegated merely to modern IT systems. This concept is blatantly prevalent in things we come across every day, even though we may not realize it. Since I live and work in Park Ridge, a very close suburb of Chicago, IL (USA) , examples of the aforementioned are not hard to come by.
I happened to attend a Microsoft seminar in Chicago today, and had to take a drive over to the parking garage so I could hop on a CTA train, our local transit system for the city. On my way there, I had to pass numerous intersections with stoplights. These intersection stoplight systems are built for resiliency in the way that each intersection has multiple sets of stoplights for a given direction. Two sets are fairly common; major intersections may even carry three sets per direction. One failing still keeps traffic moving.
The gatekeeper at the parking garage was an entry ticket system, so that one can pay upon exit. There were two such machines on separate lanes, and as luck would have it, one was down and out with a cone blocking that lane -- so all cars were passing through a single ticket machine this morning. The larger system as a whole hit a snag, but continued operating in a delayed but functional manner.
The CTA train system in Chicago, while having numerous faults with its financials and politics, is fairly intelligently built from an engineering viewpoint. Each train line on the system has at two tracks, one going "inward" towards the city center, and one going "outward" to the phalanges of the city.
During normal operation the tracks are used concurrently for two-way passenger flow, but when problems like accidents or outages hit a track, both directions' trains can pass back and forth on a single track for smaller stretches at a time. Slow, but still resilient in the truest sense.
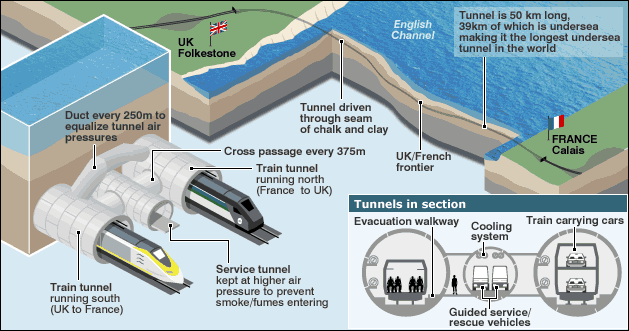
Ever travel on the Chunnel that connects France and England? It happens to be the largest underwater tunnel in the world, and is likewise one of the biggest resiliency engineering achievements of modern time. It's powered by redundant power sources, and features a triple-tunnel design -- two for normal operation, with a third emergency backup in times of crisis. An otherwise dangerous passage is made extremely safe via rigorous resiliency planning. (Image Source: BBC)
The CTA system straddles the famous Kennedy expressway that heads into the inner city, which is another system built for resiliency in time of need. When repairs close down lanes, traffic still flows. And heavily congested parts of the expressway feature "express lanes" which are usually used to carry overflow traffic in the direction heavily needed during certain times (generally inward during the morning, and outward from the city center in the afternoon). If disaster strikes or other issues close down too many normal lanes, these "express lanes" can be used to provide additional capacity. Again, resilient by design.
Numerous other complex systems in our daily lives, such as airplanes, follow very similar engineering logic. Due to the inherent dangers of having single points of failure while 30,000 ft in the air, planes almost always now have most core backbone aspects either duplicated, or even triplicated. Core infrastructure needs on planes like power systems, air systems, hydraulics and other pieces have two to three layers of redundancy for unmatched resiliency in the face of failure during life threatening situations.
Not surprisingly, the amount of expensive engineering might that goes into every commercial airplane has led in part to airline travel being one of the safest ways to travel.
How does all of this play into modern IT platforms and systems, like company servers and networks and communications services? Resiliency planning, no matter what end form it takes, still provides similar end results.
When it comes to the kinds of small and midsize businesses we support, these results are in the form of superior uptime; reduced data loss; lower yearly maintenance fees due to a reduction in emergency labor costs; and above all, less lost productivity. These are the things that almost any small business owner truly cares about when it comes to their IT operational status.
If IT systems are only as strong as their weakest links, what do these links actually look like? Here are the ones we are routinely evaluating during upgrade cycles with customers.
Dual WANs: Resiliency for Internet Connectivity
With as many businesses moving to the cloud as is the case today, especially among our client base, the weak link in a full cloud application stack is clearly your ability to have a working internet line during the business day. Some business owners place too much reliance on half-hearted promises from providers of things like Fiber or bonded T1/T3 lines, and believe that the ISP's promise of uptime alone is worth betting your business revenue on.
Coincidence or not, time and time again I find that these same pipes that promise unmatched uptime are the ones hitting longer downtime spans compared to their less-costly counterparts like business coax. T1 lines that are down for whole mornings, or fiber runs that were mistakenly cut. Whatever the excuse, placing too much trust in a single ISP of any sort is a bad plan for cloud-heavy businesses.
The alternative? Stop wasting money on premium lines like sole fiber or T3 and instead build your internet backbone in a resilient manner using dual cost effective options such as business coax and metro ethernet lines. In conjunction, a 20-40 person office can easily be run off of two connections which together run in the upper hundreds of dollars range instead of the thousands of dollars range, with better uptime overall and speeds that are near equal to their premium counterparts (barring Fiber at the higher levels, which is out of question for most small businesses anyway).

Meraki's firewalls are one of the best investments a company can make to enhance resiliency with dual WAN pipes, increase security through native filtering, and simplify network management. They are the only network equipment provider to fully allow for cloud management across all their devices. They are, in turn, easy to install and just as simple to support. I'll recommend them over Cisco ASAs and Sonicwalls any day of the week. (Image Source: Meraki)
We're routinely putting these dual WAN pipes into play on our firewall boxes of choice, which are units from Meraki's MX series of devices. A sub 25-person office can invest in a Meraki MX60W for just about $500 before licensing, and they can leverage intelligent internet connection bonding/failover, AutoVPN capabilities between branches, pipe-level malware filtering, and built in 802.11N wireless. Not to mention that Meraki's support is one of the best in the business from our experience.
For establishments that require 24/7 operation and cannot have any downtime, such as hospitals, we are even going so far as to implement high availability between multiple firewalls which adds complexity, but achieves near 100 percent levels of internet and connectivity uptime. You do have to purchase matching sets of the firewall you want to use in HA mode, but Meraki doesn't ask you to buy dual licenses -- making HA a cost effective option for something that used to be only viable for the enterprise.
NIC Teaming: Resiliency Between Network Components
Most new servers these days come with at least two NIC ports on the back. For higher end boxes, 3-4 NICs isn't that uncommon. And what do most customers do with all but port number 1? Nothing, to be precise.
While implementing resiliency in the form of NIC teaming used to be a touchy and daunting affair, back in the Server 2003/2008 days, Microsoft has brought the technology to the masses. Instead of placing reliance on the NIC makers and their sometimes-pitiful drivers, Microsoft now offers NIC teaming capability as part of the core Server 2012 and 2012 R2 experience. It's a mere click-click-click affair and it has worked flawlessly on each install we've done.
The core tenet of NIC teaming is to provide multiple resilient points of failure in a network communications path to and from servers, and even between switches and firewalls. It's not feasible to implement multiple switches per network segment for most small businesses, but there is no excuse now NOT to be using NIC teaming in Server 2012 R2.
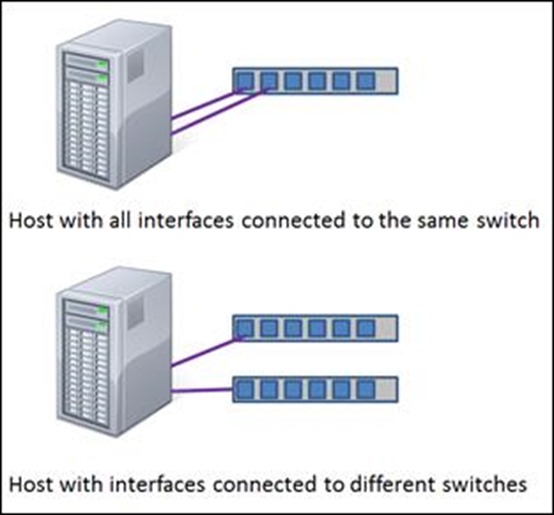
NIC teaming used to be a messy affair on servers. You needed special drivers, complex configuration, and the right mix of luck. That's all a thing of the past. Every new server we deploy now is setup for NIC teaming by default, as Server 2012 R2 has it baked into the core OS -- no special crazy drivers required. As shown above, you can opt to connect both NICs on a server to the same switch, but for the less cost-sensitive, going across two switches is ideal as it further increases resiliency in the face of switch failure. (Image Source: TechNet Building Clouds Blog)
The form of NIC teaming on Server 2012 R2 which we love using the most, Switch Independent mode, allows this feature to be used with any dummy (unmanaged) switch and still function how it was meant to work. When two (or more) NIC links are active and connected from a given server they work in a load-balanced manner, providing additional bandwidth to and from the server.
If a link failure happens, either from a bad ethernet cable or switch port (or downed switch, in the case of multiple independent switches), the server can actively route all traffic blindly over the remaining working link or links. I won't go into the technical nitty gritty, as you can read about it on this great blog post, but the feature is probably one of my favorite aspects of Server 2012 (it's hard to pick just one).
If you have decent managed switches at your disposal, you can create bonded links using multiple ports with commonplace technology known as LAG. The implementation and technology behind LAG varies from switch maker to switch maker, but the core concept is the same as NIC teaming in Server 2012. Creating resiliency through pipelines that can failover in the face of disaster from a single link going down. We don't implement this often at small businesses, but it's out there and available on numerous sub $400 switches like models from Cisco Small Business, Netgear's PROSAFE series, and Zyxel's switches.
RAID & Windows Storage Spaces: Resiliency for your Data
Redundant Arrays of Independent Disks (RAID) is by far one of the most important aspects of resiliency a company should be using to keep uptime on servers and data sets at a maximum. It's proven technology, relatively inexpensive, and extremely mature. There are numerous levels of RAID available, all of which serve a different operational purpose, but RAID 1 is by far our favorite flavor of RAID to implement at the SMB level due to its simplicity and high reliability, especially when paired with SAS or SSD drives.
The concept of RAID, or specifically RAID 1, is very simple. Take two or more identical disks, employ a storage controller that can manage duplication of data between them (a RAID card, as it's called), and you've got resiliency-in-a-box for the most part. You can setup numerous storage volumes such as one for Windows, one for file serving, another for long term storage, etc. More and more, we're tying together high-end SSDs to work together in RAID 1 "pairs" -- one for Windows and HyperV, and another solely for data storage. This tag team has worked well on numerous server rollouts for us.
Many IT pros gawk when they see me mention RAID-1, but they forget the holy grail of why I love using RAID-1, as I discussed at length in a previous article. In case of disaster on a RAID-1 volume, I can easily pull a disk out of the array and recover data in next to no time, since the disk is not tied into a complex RAID set that can only be read and written from/to off the original controller card series employed in the server. The security that comes with this failsafe is well worth any of the small shortcomings of RAID-1 like slightly lesser performance.
If a disk in a RAID setup fails, we merely go in and replace the failed drive, the array rebuilds, and we are back in business. No expensive downtime. No costly repairs. It's a tried and true method of keeping critical systems humming, and for some time, this was the only method we would rely on for such resiliency at the hard disk level.
Who needs an expensive SAN? Windows Server 2012 and 2012 R2 offer Storage Spaces, a cool new technology that lets you build your own resilient storage backbone out of inexpensive drives. We've been using it as an alternative to RAID for our primary client file backup data at our office, and it hasn't suffered a hiccup in nearly a year. We opted to use Microsoft's new ReFS instead of NTFS for the filesystem, and this affords for increased reliability and resiliency of the underlying data. Microsoft got this new technology pretty right. (Image Source: TechNet)
Recently, Microsoft has introduced a very interesting, and so far very-stable option to using large RAID arrays for data storage (and SANs, for those businesses that have investigated them) called Storage Spaces. It has been baked into Server 2012 and Server 2012 R2 and our own internal production server has been using it for critical data storage for most of the last year.
Storage Spaces is a build-your-own alternative to expensive high end RAID arrays and SANs (codeword for nasty expensive storage banks that enterprises buy) which you can piece together with nothing more than servers, loads of standard SAS/SATA/SSD disks (you CAN mix and match), and Windows Server 2012 and up.
I won't dive into the finer tenets of Storage Spaces, as you can read about my thoughts on this excellent new technology and why I think it's near ready as a prime alternative to RAID for data storage needs.
I got a lot of emails from readers after that article asking about whether Windows itself can be installed on a Storage Space, and at least for now, the answer is no. With the improvements being made to SS and the underlying replacement to NTFS, ReFS, I would not be shocked if this will be possible soon.
When that happens, hopefully in the next release of Windows Server, we may be ditching RAID entirely. But do know that there are two great options for introducing enterprise class resiliency to your small business IT systems.
Dual Power Supplies: Resiliency for Server Power
This is considered a premium option on servers, but one that we almost always recommend these days for any physical boxes we install. Our favorite go-to servers are Dell PowerEdge boxes, as they are relatively cost friendly and provide such premium features like dual power supplies. Coupled with a 3 or 5 year warranty, we can have replacements in hand for any downed PSUs in a matter of a day at most with no strings attached.
Most cheap servers employ the use of a single standard power supply, just like what any standard desktop or laptop has. But if you are running your company's primary applications or data from a single or few critical servers, is praying for the best and hoping a PSU doesn't blow out really a contingency plan? I think not.

Dual PSUs on a server renders the same purpose as dual network cards: in the face of one failing, you don't have to incur damaging downtime or worse, lick the costs of emergency repair labor. A downed power supply merely alerts you via noise or flashing lights and a software alert, and a spare can be purchased and installed with ease; no downtime required. Running a server without dual PSUs is manageable, but only if you have a hot spare replacement on hand and ready to go, which most businesses trying to save a buck don't. (Image Source: StorageReview.com)
A good PowerEdge or similar server with dual slide-in power supplies will raise the price tag of the box by a good 10-20 percent, but it's almost surely money well spent. Not only are the units easier to replace when they go down, which reduces labor costs, but it also prevents downtime because a server can stay operational when a single power supply fails out of the blue.
And don't tell me your business doesn't care about downtime. It's likely that you probably just don't know what an hour of lost productivity actually costs your business. The Ponemon Institute, a fairly well regarded independent IT research tank, pits the most recent average cost of per-minute downtime at $7900. This is most obviously swayed due to the number of Enterprises factored into the figure, but you get the picture. The calculations to run your own downtime figures are shown here.
So is skimping on the extra couple hundred bucks on that new server truly worth it? Run your numbers and then get back to me.
Virtualize your Servers: Resiliency For Production Workloads
The argument for purchasing a new server for every extra need your business may have -- whether it be an additional file server, application server, devops environment, print server, etc -- is old hat and antiquated. While there is something to be said for keeping one or two solid servers on-premises to power your workloads, we consult with too many clients that are stuck in a 1990s mentality that a server a day keeps the doctor away.
Just the opposite, in fact. Physical servers not only are raw capital outlays that must be purchased and likely amortized, but they have loads of other needs that balloons their operating costs over 3-5 year cycled timespans. Electricity isn't free. Licensing isn't free. Security software isn't free. Backup, maintenance, configuration, and replacement just add to this mess. If you saw the total figures for what each physical server ran your company over the last three years, you'd be quite surprised.
Instead of building out on extra boxes, we should be in a mindset of building up by scaling out virtualized workloads on beefier servers. Our favorite hypervisor for getting this done is Hyper-V, the free hypervisor Microsoft bundles into every copy of Windows Server since 2008. We've got numerous clients in the field using HyperV on Server 2012 (and 2012 R2) who are running Remote Desktop Services servers, print servers, application servers, and much more.
The other big nicety? Every copy of Windows Server 2012 and 2012 R2 allows for up to (2) virtual server instances to be loaded and fully licensed. That's right. You only need to purchase (1) copy of Server 2012/Server 2012 R2 and you have out of the box rights for two more VMs on top of it, for a total of (3) instance of Windows Server at your disposal. That's a deal if I've ever seen one, and we take advantage of it for nearly every customer that gets a new server.
We have a client right now that has a separate 2003 Terminal Services box, a 2008 primary AD/file server and a Windows 8.1 "phone server" that is hosting their PBX software. We will be consolidating all of that onto a single repurposed IBM server running 2012 R2 and HyperV hosting the virtualized aspects.
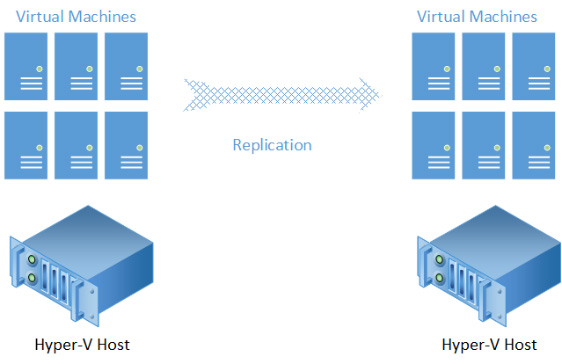
The ultimate aspect of resiliency through Hyper-V is the functionality known as Hyper-V Replica which serves the same purpose as its name implies: replicate virtual machines between physical hosts across your office network, or even across branches. Unparalleled uptime matched with universal portability of virtual machines means your server is never tied to a physical box like we used to think with the notion of the "back closet server." (Image Source: Microsoft Press)
Where's the resiliency in hosting servers virtually? The benefits are endless. Virtual Machines are hardware-agnostic, which means a Dell PowerEdge can spin up a VM, which can then be passed off to an IBM server, and the chain can continue as and when necessary. The power of NIC teaming can be taken advantage of, along with other benefits of Hyper-V software defined networking.
For those with large, mission critical workloads that are 24/7 and need very high availability, you can employ out of the box features that HyperV offers like clustering where numerous virtual machines can provide a load balanced VM set for a given purpose. VMs can be live-migrated between servers which means you don't even have to take the server down for migration, meaning end users are not impacted in any way.
While Microsoft has yet to publicly release the technology, I have heard slivers of rumors from IT pros with connections at Microsoft that Azure is preparing to accept live-migration workloads from on-premise servers, which means you can ideally transition your workloads into and off of Azure on the fly. This will be very neat once released and I'm anxiously awaiting the announcement once this is ready.
In the End, Resiliency is Both Technology And Methodology
Just like money alone won't solve all ills, nor will whiz-bang technology. A dual-WAN capable Meraki firewall is only as powerful as the planning put into how two internet lines will work in unison and the subsequent configuration implemented. And the same goes for anything else, like a fancy dual PSU server or switches capable of LAG between one another, keeping in mind the upstream/downstream devices at each part of this logical "chain".
Resiliency through redundantly designed systems can only be achieved when coupled with proper planning, and more succinctly, a methodology for the level of resiliency a small business is planning to achieve through technology. Some questions a business owner should be asking prior to purchasing ANY kind of solution should be:
- What does an hour of downtime cost our business?
- How many "weak links" are we willing to accept in our network and server design?
- What is our cost threshold for implementing resilient systems capable of keeping us operational?
- Do we have any pieces of core infrastructure that can be re-purposed to provide better resiliency, like managed switches not using LAG yet, or servers that don't have NIC Teaming turned on yet?
- What is the cost-benefit analysis of any upgrade to achieve resiliency, such as the amount of savings from having a server that doesn't need emergency service for a downed power supply or broken hard drive to get the business back up?
- Do any proposed aspects of resiliency introduce fringe benefits, like Hyper-V's ability to have VMs moved between hosts for future needs?
Without answers to the above, toiling over the joys of all the fancy equipment out there is fruitless for a long term approach. Piecing together one-off solutions that don't fit the agreed-upon needs of the organization may increase short term resiliency, but increase long term costs due to potential early replacement necessary and associated downtime, to name a few ills we've seen from lackluster planning.
Better yet, instead of having to redouble on efforts to incorporate systems with resiliency, spend the extra money to get equipment that offers the option to enable resiliency down the road. Don't need that Meraki firewall yet because you don't have dual internet connections at the office? So what -- buy the better firewall and enabling the option will take a mere couple hours to configure and test, with zero downtime to normal operation.
Making sensible decisions up front during upgrade cycles, especially when planning out server and networking purchases, can go a long way in saving time, energy, and expense down the road, either from replacement needed or from outage costs both in productivity and emergency labor.
If I got a dime for every time I had to tell a customer, while explaining emergency labor costs, "I told you so," I just very well may be rich by now. Or close to it.
Image Credit: frank_peters/ Shutterstock
 Derrick Wlodarz is an IT Specialist who owns Park Ridge, IL (USA) based technology consulting & service company FireLogic, with over eight+ years of IT experience in the private and public sectors. He holds numerous technical credentials from Microsoft, Google, and CompTIA and specializes in consulting customers on growing hot technologies such as Office 365, Google Apps, cloud-hosted VoIP, among others. Derrick is an active member of CompTIA's Subject Matter Expert Technical Advisory Council that shapes the future of CompTIA exams across the world. You can reach him at derrick at wlodarz dot net.
Derrick Wlodarz is an IT Specialist who owns Park Ridge, IL (USA) based technology consulting & service company FireLogic, with over eight+ years of IT experience in the private and public sectors. He holds numerous technical credentials from Microsoft, Google, and CompTIA and specializes in consulting customers on growing hot technologies such as Office 365, Google Apps, cloud-hosted VoIP, among others. Derrick is an active member of CompTIA's Subject Matter Expert Technical Advisory Council that shapes the future of CompTIA exams across the world. You can reach him at derrick at wlodarz dot net.