
6 design principles for machine learning anomaly detection systems

Every year, 22 percent of eCommerce customers abandon their shopping carts due to website errors. Every year, insurance companies discharge up to 10 percent of their claims cost on fraudulent claims. Network outages cost up to $5,600 per minute. These and other failures represent anomalies that are detectable by machine learning in ways that human-powered monitoring can’t replicate.
When it comes to deploying a machine learning anomaly detection system, companies have the choice of either purchasing a ready-made system or developing their own. No matter what they choose, however, the resulting system should be based on criteria that account for their company’s size, needs, use cases and available resources. Here are the six principles that companies should pay attention to:
1. Timeliness
Here’s a statistic from the cybersecurity world -- it takes an average of 206 days to detect a data breach or a malware infestation. The anomalies that you’re worried about might not specifically be data breaches, but they have similar effects in that they demoralize your customers, cause losses in productivity and cause your company to lose revenue. Do you want a money-losing anomaly to linger in your system for the better part of a year?
It’s worth considering how much time you need. In other words, do you need to learn about anomalies quickly -- or right away? To do it quickly, within days or hours, requires batch-processing. To do it right away, you need to conduct analysis with real-time data.
2. Scale
Scale is going to be a highly individual decision for most companies. It depends both upon the size of your organization at the present and how much you believe you’ll grow (this can be a highly subjective opinion). Essentially, are you currently analyzing thousands of records or millions? How much do you expect that number to increase?
Based on what you choose, batch processing versus real-time data is going to be a factor once again. As far as batch processing is concerned, it’s easier to process smaller batches. Real-time data doesn’t have as much of a problem – it produces a result as soon as it gets a data point, making it scalable.
3. Rate of Change
Does your data experience seasonality, with large ebbs and flows as people leave work and start shopping, catch wind of sales and find fad products and novelties that they love? Or is it more like a constant and predictable hum of incoming traffic?
In our experience, most corporate data is in constant flux, but the difference is in the rate of change. eCommerce systems change quickly while manufacturing data changes slowly, because manufacturing is a relatively closed system -- each machine does the same action time after time unless something breaks or someone changes its settings. As you may imagine, it’s easier to pick anomalies out of this kind of data.
For example, in this graph, it’s clear that there was a fairly consistent pattern that completely changed it’s behavior suddenly, and it remained that way for a prolonged period of time.
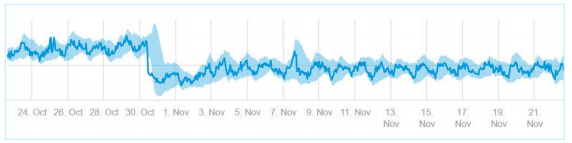
Online companies may need different kinds of algorithms. When "normal" behavior looks different every day, companies will need algorithms that can adapt in order to screen out ordinary changes in data from changes that could harm customers and damage revenue.
4. Conciseness
Part of what makes anomaly detection so useful is its ability to draw conclusions while mostly untethered from human oversight. Here’s the thing -- your system can look at any number of metrics and determine whether they are producing anomalies, but the way that it presents anomalies to you is also important.
For example, imagine an eCommerce site that’s seeing an anomalous decline in visitors. That’s something that your system should certainly notify you about -- but a single alert about a drop in site visitors doesn’t say much. In addition, there are usually a number of problems happening at the same time -- customers are abandoning their carts, they’re experiencing larger than normal amounts of latency, there’s a spike in returns, etc.
If your system just spits out the above information as a storm of unrelated alerts, it’s going to be hard to put the puzzle pieces together. In a situation where every second costs money, this is less than productive. Machine learning systems can be smart enough to package separate anomalies into a single alert and draw conclusions about the source of a problem, so it’s worth investing in those capabilities -- often referred to as "correlation" or "root cause analysis".
5. What is An Anomaly?
It is hard to define what constitutes an anomaly, and it’s even more difficult to find the cause.
Most people agree that things like declining site visits, abandoned carts and network latency are anomalies. But to what degree does each constitute an anomaly for your company? The definition of an anomaly is highly subjective. For instance, look at the figure below. Each image is a dog (a good dog!) but each individual dog could be construed as an anomaly. The puppy is an outlier because it’s young, the retriever is the only one holding tennis balls, and the pit-mix is the only one wearing a costume.

It might seem as though you’re the only one who can tell the machine learning anomaly detection system what constitutes an anomaly. Unfortunately, under most circumstances, your anomaly detection system will have to determine what normal behavior looks like on its own.
6. Contextual Analysis
Supervised learning methods -- where you tell your machine learning software exactly what constitutes an anomaly -- are only practicable under rare conditions. Only the most simple applications have a known and categorized number of failure states. Most application stacks are so complex that it’s impossible to describe the number of ways in which they can fail. Therefore, most organizations default to unsupervised techniques.
In an unsupervised learning method, the system autonomously reviews data from an application stack and then categorizes it as being either anomalous or not. For example, the system would look at every individual dog photo in the gallery above and decide for itself whether it had turned up an anomalous dog. These systems cast a wide net and are capable of turning up nearly any anomaly -- along with quite a few false positives.
Semi-supervised learning allows human participants to create a feedback loop. They can say, "only these dogs represent anomalies," in other words. If the model indicates a false positive, the human monitor can send it back as "not an anomaly." The model will take this feedback into account and adjust, improving its accuracy over time.
The benefits of building or purchasing a semi-supervised machine learning system are immense, especially for businesses with a complex application infrastructure. The results are the best way to understand the success of ML -- Amazon has used ML to decrease their "click to ship" time by 225 percent, and 83 percent of AI early adopters report either moderate or substantial economic benefits. In other words, those that use machine learning to refine their understanding of their complicated application stacks rapidly begin to outcompete those who don’t.
Image credit: Jirsak/depositphotos.com
 Ira Cohen is chief data scientist and co-founder of Anodot, where he develops real-time multivariate anomaly detection algorithms designed to oversee millions of time series signals. He holds a PhD in machine learning from the University of Illinois at Urbana-Champaign and has more than 12 years of industry experience.
Ira Cohen is chief data scientist and co-founder of Anodot, where he develops real-time multivariate anomaly detection algorithms designed to oversee millions of time series signals. He holds a PhD in machine learning from the University of Illinois at Urbana-Champaign and has more than 12 years of industry experience.