
Red Hat takes over IBM

So IBM is buying Red Hat (home of the largest Enterprise Linux distribution) for $34 billion and readers want to know what I think of the deal. Well, if I made a list of acquisitions and things to do to save IBM, buying Red Hat would have been very close to the top of that list. It should have bought Red Hat 10 years ago when the stock market was in the gutter. Jumping the gun a bit, I have to say the bigger question is really which company’s culture will ultimately dominate? I’m hoping it’s Red Hat.
The deal is a good fit for many reasons explained below. And remember Red Hat is just down the road from IBM’s huge operation in Raleigh, NC.
Remembering Paul Allen

Microsoft co-founder Paul Allen died on Monday at age 65. His cause of death was Non-Hodgkins Lymphoma, the same disease that nearly killed him back in 1983. Allen, who was every bit as important to the history of the personal computer as Bill Gates, had found an extra 35 years of life back then thanks to a bone marrow transplant. And from the outside looking-in, I’d say he made great use of those 35 extra years.
Of all the early PC guys, Allen was probably the most reclusive. Following his departure from Microsoft in 1983 I met him only four times. But prior to his illness Allen had been a major factor at Microsoft and at MITS, maker of the original Altair 8800 microcomputer for which Microsoft provided the BASIC interpreter and where Allen was later head of software.
How to cut the cable yet stay within your bandwidth cap

After 31 years of doing this column pretty much without a break, I’m finally back from a family crisis and moving into a new house, which sadly are not the same things. Why don’t I feel rested? I have a big column coming tomorrow but wanted to take this moment to just cover a few things that I’ve noticed during our move.
We have become cable cutters. Before the fire we had satellite TV (Dish) and could have kept it, but I wanted to try finding our video entertainment strictly over the Internet. It’s been an interesting experience so far and has taught us all a few lessons about what I expect will be an upcoming crisis of people blowing past their bandwidth caps.
Cloud computing may finally end the productivity paradox

One of the darkest secrets of Information Technology (IT) is called the Productivity Paradox. Google it and you’ll learn that for at least 40 years and study after study it has been the case that spending money on IT -- any money -- doesn’t increase organizational productivity. We don’t talk about this much as an industry because it’s the negative side of IT. Instead we speak in terms of Return on Investment (ROI), or Total Cost of Ownership (TCO). But there is finally some good news: Cloud computing actually increases productivity and we can prove it.
The Productivity Paradox doesn’t claim that IT is useless, by the way, just that we tend to spend more money on it than we get back in benefits from those expenditures. IT still enabled everything from precision engineering to desktop publishing to doctoring movie star photos, but did so at a considerable cost. Follow the history of any organization more than 50-60 years old and you’ll see that they acquired along the way whole divisions devoted not to manufacturing or sales but just to schlepping bits and keeping them safe. Yes, IT reduced the need for secretaries, telephone operators, and travel agents, but it more than replaced those with geeks generally making higher wages.
GDPR kills the American internet: Long live the internet!

I began writing the print version of this rag in September, 1987. Ronald Reagan was President, almost nobody carried a mobile phone, Bill Gates was worth $1.25 billion, and there was no Internet in the sense we know it today because Al Gore had yet to "invent" it. My point here is that a lot can change in 30+ years and one such change that is my main topic is that, thanks to the GDPR, the Internet is no longer American. We’ve lost control. It’s permanent and probably for the best.
Before readers start attacking, let’s first deal with the issue of Al Gore and the Internet. What Gore actually said to Wolf Blitzer on CNN in March, 1999 was "During my service in the United States Congress, I took the initiative in creating the Internet." And he did. In 1986-1991 Gore sponsored various bills to both expand and speed-up what had been the ARPAnet and allow commercial activity on the network.
The space race is over and SpaceX won

The U.S. Federal Communications Commission (FCC) recently gave SpaceX permission to build Starlink -- Elon Musk's version of satellite-based broadband Internet. The FCC specifically approved launching the first 4,425 of what will eventually total 11,925 satellites in orbit. To keep this license SpaceX has to launch at least 2,213 satellites within six years. The implications of this project are mind-boggling with the most important probably being that it will likely result in SpaceX crushing its space launch competitors, companies like Boeing and Lockheed Martin's United Launch Alliance (ULA) partnership as well as Jeff Bezos' Blue Origin.
Starlink is a hugely ambitious project. It isn't the first proposed Internet-in-the-sky. Back in the 1990s a Bill Gates-backed startup called Teledesic proposed to put 840 satellites in orbit to provide 10 megabit-per-second (mbps) broadband anywhere on Earth. Despite spending hundreds of millions, Teledesic was just ahead of its time, killed by a lack of cost-effective launch services. Twenty years later there are several Teledesic-like proposals, the most significant of which may be OneWeb -- variously 882 or 648 or 1972 satellites, depending who is talking, offering 50 mbps. OneWeb has raised more than $1 billion, found a launch partner in Arianespace and even broken ground on a satellite factory in Orlando, Florida.
The real problem with self-driving cars

Whatever happened to baby steps?
Last week a 49 year-old Arizona woman was hit and killed by an Uber self-driving car as she tried to walk her bicycle across a road. This first-ever fatal accident involving a self-driving vehicle and a pedestrian has caused both rethinking and finger-pointing in the emerging industry, with Uber temporarily halting tests while it figures out what went wrong and Google’s Waymo division claiming that its self-driving technology would have handled the same incident without injury. Maybe, but I think the more important question is whether these companies are even striving for the correct goal with their cars? I fear that they are over-reaching and simply trying to do too much too soon.
Facebook, Cambridge Analytica and our personal data
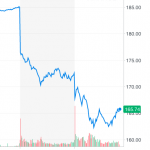
Facebook shares are taking it on the chin today as the Cambridge Analytica story unfolds and we learn just how insecure our Facebook data has been. The mainstream press has -- as usual -- understood only parts of what’s happening here. It’s actually worse than the press is saying. So I am going to take a hack at it here. Understand this isn’t an area where I am an expert, either, but having spent 40+ years writing about Silicon Valley, I’ve picked up some tidbits along the way that will probably give better perspective than what you’ve been reading elsewhere.
Much of this is old news. There are hundreds -- possibly thousands -- of companies that rely on Facebook data accessed through an Application Programming Interface (API) called the Graph API. These data are poorly protected and even more poorly policed. So the first parts of this story to dispel are the ideas that the personality test data obtained by Cambridge Analytica were in any way unusual or that keeping those data after their sell-by date was, either. That doesn’t necessarily make the original researcher without blame, but the Cambridge folks could have very easily found the same data elsewhere or even generated it themselves. It’s not that hard to do. And Facebook doesn’t have a way to make you throw it away (or even know that you haven’t), either.
Stephen Hawking and me

I only met Stephen Hawking twice, both times in the same day. Hawking, who died a few hours ago, was one of the great physicists of any era. He wrote books, was the subject of a major movie about his early life, and of course survived longer than any other amyotrophic lateral sclerosis (ALS) sufferer, passing away at 76 while Lou Gehrig didn't even make it to 40. We’re about to be awash in Hawking tributes, so I want to share with you my short experience of the man and maybe give more depth to his character than we might take away from the evening news.
Several years ago I was booked to speak at a (pre-Intel) Window River Systems event at the Claremont Hotel in Oakland. The Claremont, like the Hotel Del Coronado in San Diego, is a huge old hotel built entirely of wood. Creaky old elevators and creaky old staircases connect all the floors but stairs are faster and I was in a hurry to give my speech because Jerry Fiddler was waiting. So I took the stairs two at a time then burst through a set of double doors and straight into…
We win, you lose: How shareholder value screwed the middle class
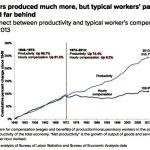
The American Dream changed somehow in the 1970s when real wages for most of us began to stagnate when corrected for inflation and worker age. My best financial year ever was 2000 -- 18 years ago -- when was yours? This wasn’t a matter of productivity, either: workers were more productive every year, we just stopped being rewarded for it. There are many explanations of how this sad fact came to be and I am sure it’s a problem with several causes. But this column concerns one factor that generally isn’t touched-on by labor economists -- Wall Street greed.
Lawyers arguing in court present legal theories -- their ideas of how the world and the law intersect, and why this should mean their client is right and the other side is wrong. Proof of one legal theory over another comes in the form of a verdict or court decision. As a culture we have many theories about institutions and behaviors that aren’t so clear-cut in their validity tests (no courtroom, no jury) yet we cling to these theories to feel better about the ways we have chosen to live our lives. In American business, especially, one key theory is that the purpose of corporate enterprise is to "maximize shareholder value." Some take this even further and claim that such value maximization is the only reason a corporation exists. Watch CNBC or Fox Business News long enough and you’ll begin to believe this is God’s truth, but it’s not. It’s just a theory.
Predictions #8-10: Apple, IBM & Zuckerberg

It’s time to wrap up all these 2018 predictions, so here are my final three in which Apple finds a new groove, IBM prepares for a leadership change, and Facebook’s Mark Zuckerberg gives up a dream.
Apple has long needed a new franchise. It’s been almost eight years since the iPad (Apple’s last new business) was introduced. Thanks to Donald Trump’s tax plan, Cupertino can probably stretch its stock market winning streak for another 2-3 years with cash repatriation, share buy-backs, dividend increases and cost reductions, but the company really needs another new $20+ billion business and it will take every one of those years to get a new one up to scale.
Prediction #7 -- 2018 will see the first Alexa virus
There’s a new Marvel superhero series on Fox called The Gifted that this week inspired my son Fallon, age 11, to predict the first Alexa virus, coming soon to an Amazon Echo, Echo Dot or Echo Show cloud device near you. Or maybe it will be a Google Home virus. Fallon’s point is that such a contagion is coming and there probably isn’t much any of us -- including both Amazon and Google -- can do to stop it.
The Gifted has characters from Marvel’s X-Men universe. They are the usual mutants but the novel twist in this series is that some of these particular mutants are able to combine their powers with terrible effect. They just hold hands, get angry, and it is mayhem squared.
Prediction #6 -- AI comes of age, this time asking the questions, too
Paul Saffo says that communication technologies historically take 30 years or more to find their true purpose. Just look at how the Internet today is different than it was back in 1988. I am beginning to think this idea applies also to new computing technologies like artificial intelligence (AI). We’re reading a lot lately about AI and I think 2018 is the year when AI becomes recognized for its much deeper purpose of asking questions, not just finding answers.
Some older readers may remember the AI bubble of the mid-1980s. Sand Hill Road venture capitalists invested (and lost) about $1 billion in AI startups that were generally touted as expert systems. An expert system attempted to computerize professional skills like reading mammograms or interpreting oil field seismic logs. Computers were cheaper than medical specialists or petroleum geologists, the startup founders reckoned, so replacing these professionals would not only save money, it would allow much broader application of their knowledge. Alas, it didn’t work for two reasons: 1) figuring-out how experts make decisions was way harder than the AI researchers expected, and; 2) even if you could fully explain the decision-making process it required a LOT more computing power than originally expected. Circa 1985 it probably was cheaper to hire a doctor than to run a program to replace one.
2018 Prediction #5 -- The H-1B visa problem will NOT go away
I’m sorry this year’s predictions seem to this point to mainly have to do with policies rather than products, but I don’t get to make the future, just predict it, and in this case I’m predicting that immigration reform will have little actual effect on H-1B visa abuse.
For those of you who aren’t already asleep I’ll start with the Cliff Notes version of the H-1B issue, which I have written about ad nauseam as you can read here (notice there are three pages of columns, so dig deep). H-1B is a U.S. immigration program to allow 65,000 foreign workers into the USA each year for up to six years, which means that at any moment there are almost 400,000 of these folks working at the desk next to yours. Some people claim that H-1Bs take jobs better filled by U.S. citizens and some feel that H-1Bs are essential for the functioning of technology industries that would otherwise be devoid of needed talent. I am clearly on the side of the former folks who see H-1Bs as a scam intended to take jobs away from, well, me.
Prediction #4 -- Bitcoin stays crazy until traders learn it is not a currency
2017 was a wild ride for cryptocurrencies and for Bitcoin in particular, rising in price at one point above $19,000 only to drop back to a bit over half of that number now. But which number is correct? If only the market can tell for sure -- and these numbers are coming straight from the market, remember -- what the heck does it all mean? It means Bitcoin isn’t a currency at all but traders are pretending that it is. 2018 will see investors finally figure this out.
Confusion abounds, so let’s cut through the crap with an analogy. Cryptocurrencies like Bitcoin, Ethereum and a ton of others operate almost exactly like a market that uses only U.S. one dollar bills and doesn’t allow exchanging those bills… ever. If you need five dollars, that will be five one dollar bill, please. If you need less than a dollar then you and your counter-party have to agree how much of a one dollar bill you each own. And they aren’t just any one dollar bills: they are specific bills, each with its own unique serial number that can be checked against a U.S. Treasury database to make sure the money is real -- that it is actually worth a dollar.
Robert X.'s Bio
Robert Cringely has worked in and around the PC business for more than 30 years. His work has appeared in The New York Times, Newsweek, Forbes, Upside, Success, Worth, and many other magazines and newspapers. Most recently, Cringely was the host and writer of the Maryland Public Television documentary “The Tranformation Age: Surviving a Technology Revolution with Robert X. Cringely.”
© 1998-2025 BetaNews, Inc. All Rights Reserved. About Us - Privacy Policy - Cookie Policy - Sitemap.